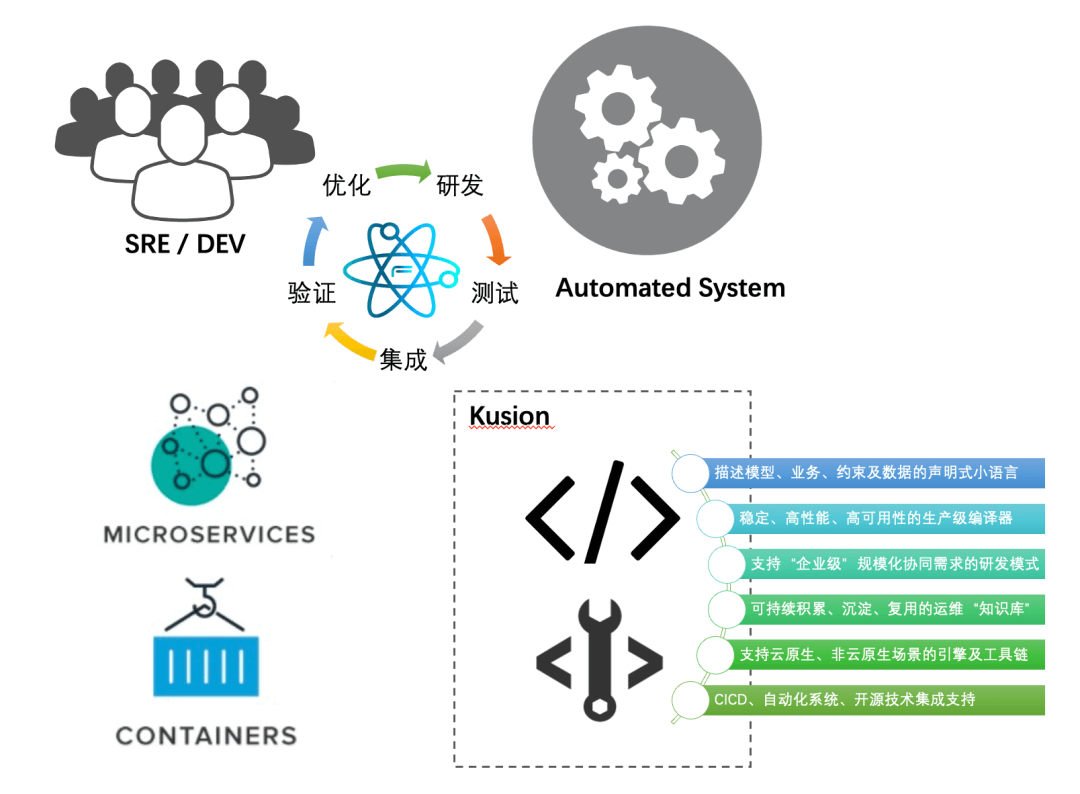
Abstract: This blog attempts to talk about the challenges and best practices in the process of large-scale platform engineering from the perspectives of engineering, programing language, divide-and-conquer, modeling, automation, and collaborative culture. Hopefully, by sharing the concepts and practices of our platform engineering with more companies and teams, we can make some interesting changes happen together.
This blog is based on the platform engineering and automation practice of KusionStack in Ant Group.
1. Platform Engineering: Making Enterprise DevOps Happen
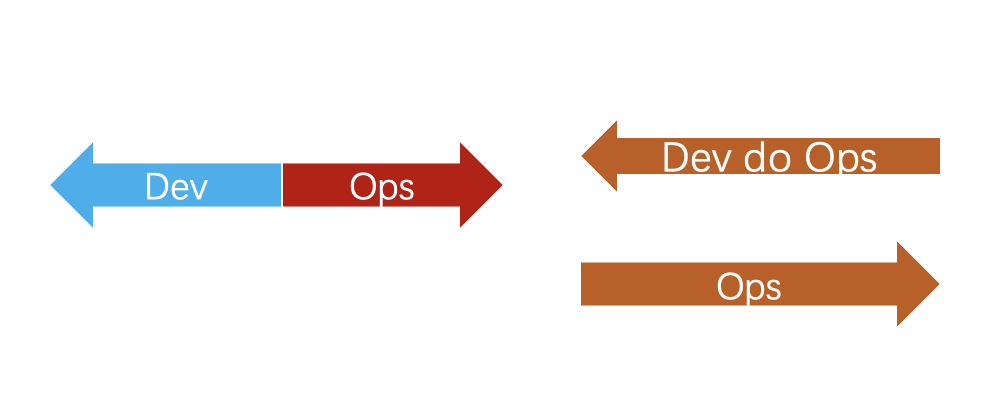
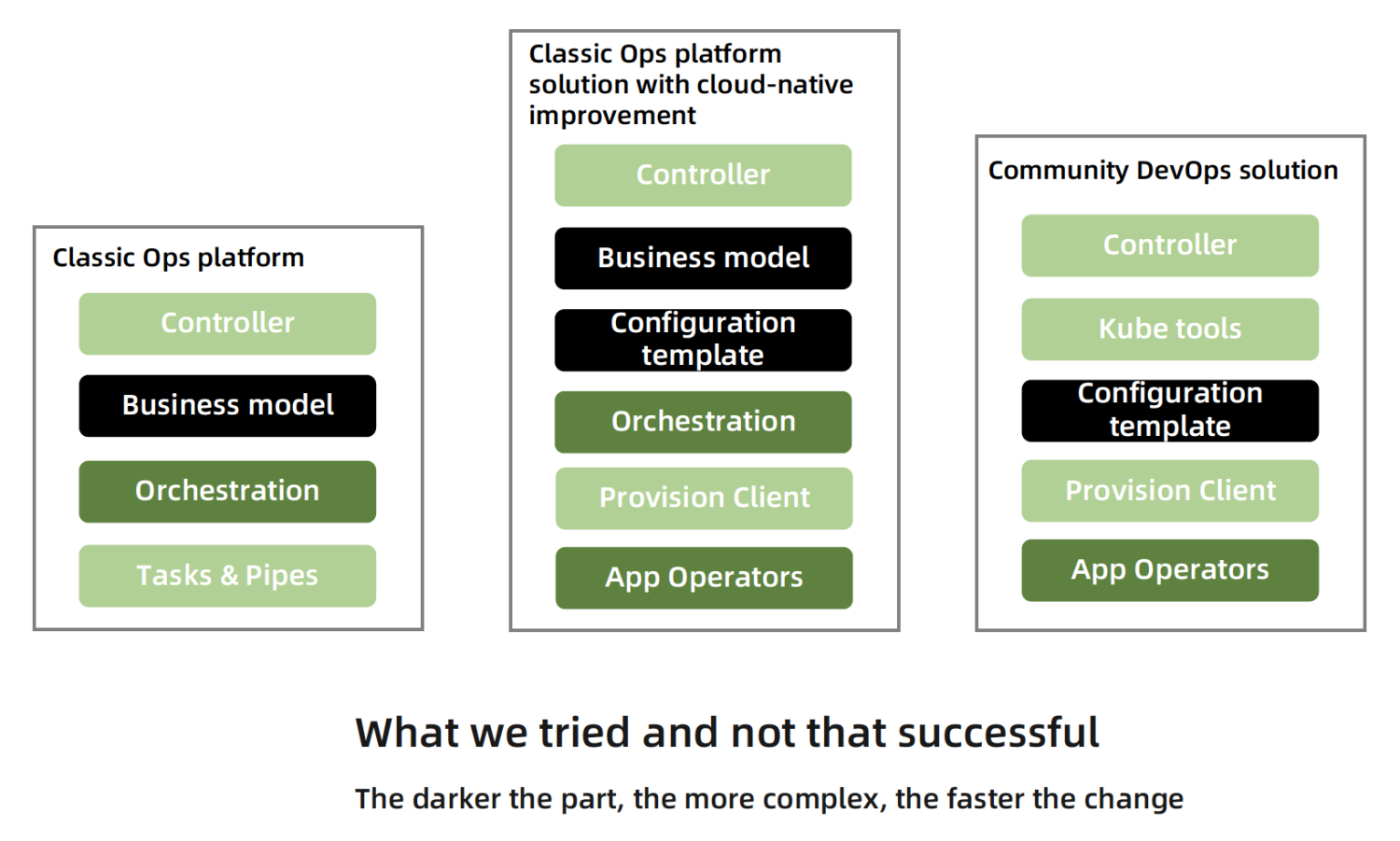
The concept of DevOps was proposed more than 10 years ago. From KVM to container to the cloud-native era, a large number of enterprises have invested in the DevOps wave to solve the dilemma of internal large-scale operation efficiency and platform construction efficiency. Most of them have fallen into some kind of Anti-Pattern based on an inappropriate understanding of DevOps, while some companies have explored their golden paths. I have experienced Anti-Patterns as shown in the figure below, where the Dev and Ops teams go their separate ways, or simply force the Dev team to handle Ops work independently. More typical classifications can be found here.
There are various reasons for difficulties achieving DevOps at scale within the enterprise, especially for companies that maintain their infrastructure within the enterprise while adopting technology platforms on the cloud. Among which, the following situations are quite common:
- The dev team and the ops team are often isolated at work and cannot reach a consensus due to team silos, lack of leaders’ insight, etc.
- The dev team leaders underestimate the professionalism, complexity and rapid changes of platform and infrastructure technology, operation and reliability work so that they push application developers to become experts with a simple DevOps understanding
- The leaders established a DevOps team, but became just middle executors, failing to make the Dev and Ops teams move forward and work closely together
- The platform dev team responds insufficiently to the business complexity due to the scale as well as to the tech complexity as a result of technological evolution, thus cannot provide effective support to application developers
- ...
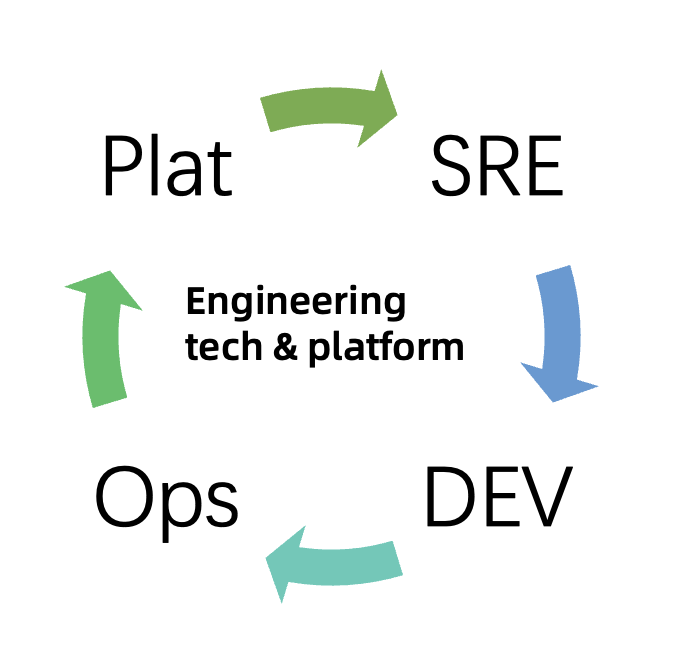
Unlike small teams working on cloud-hosted Infra services and DevOps-as-a-Service products, medium and large enterprises often need to establish an appropriate DevOps system based on their team structure and culture. Based on the successful cases, whether for Meta Dev team fully assumes the Ops function, or Google introduces the SRE team as the middle layer, Platform Engineering plays a very important role. Platform engineering aims to help enterprises build a self-service operation system for application developers, and tries to solve the following key problems through engineering tech means and workflows:
- Design a reasonable abstraction to help application developers reduce the burden of cognizing the delivery, operation, and reliability based on Infra, platform and other technologies
- Provide application developers with a unified working interface and space to avoid falling into fragmented product interfaces and complex workflows
- Help developers carry out work quickly based on internal engineering platform through effective workflow and recommended path
- Help developers manage the application life cycle through self-service CI, CD, CDRA products
- Help the platform dev team to open fundamental platform capabilities in a simple, efficient and consistent manner
- Create a culture of collaboration and sharing through training, propagation, operations, etc.
In fact, not everyone should be or could be an expert in this specific field, which turns out to be particularly hard as well. Even the experts from the platform technology team themselves are usually good at their own professional fields, especially nowadays confronting the wide adoption of cloud-native concepts and technologies, hundreds of thousands of application configurations brought by a large number of highly open and configurable platform technologies and the business complexity of the PaaS field as well as the requirements for high stability and unified governance. The purpose of platform engineering just lies in allowing application developers to participate in such large-scale DevOps work as easily and painlessly as possible. In Ant Group's practice, we tend to the following cooperative state, which is closer to Google's best practices in team structure and work mode. Platform developers and SREs become "Enablers" to support application developers to complete dev, delivery and operation in self-service. At the same time, the work results of application developers making applications deliverable and operational also become the basis for the ops team to handle application ops work. The SRE, application dev, and ops team periodically feedback the problems and pain points in the work process to the platform dev team to form a positive cycle.
2. Domain Language: A Pole of the Engineering Thought
Compared with a domain language there's no better way for open, self-service, domain-oriented business problem definitions, as well as meeting the enterprise's internal requirements of automation, low-security-risk, low noise, and easy governance. Just as there are staves for recording music, and time-series databases for storing time-series data, within the problem domain of platform engineering, a set of configuration and policy languages are created to write and manage configurations and policies at scale. Different from high-level general purpose languages with mixed paradigms and engineering capabilities, the core logic of such domain languages is to solve the near-infinite variation and complexity of domain problems with a convergent and limited set of syntax and semantics, and to integrate the ideas and methods of large-scale complex configuration and policies writing into language features.
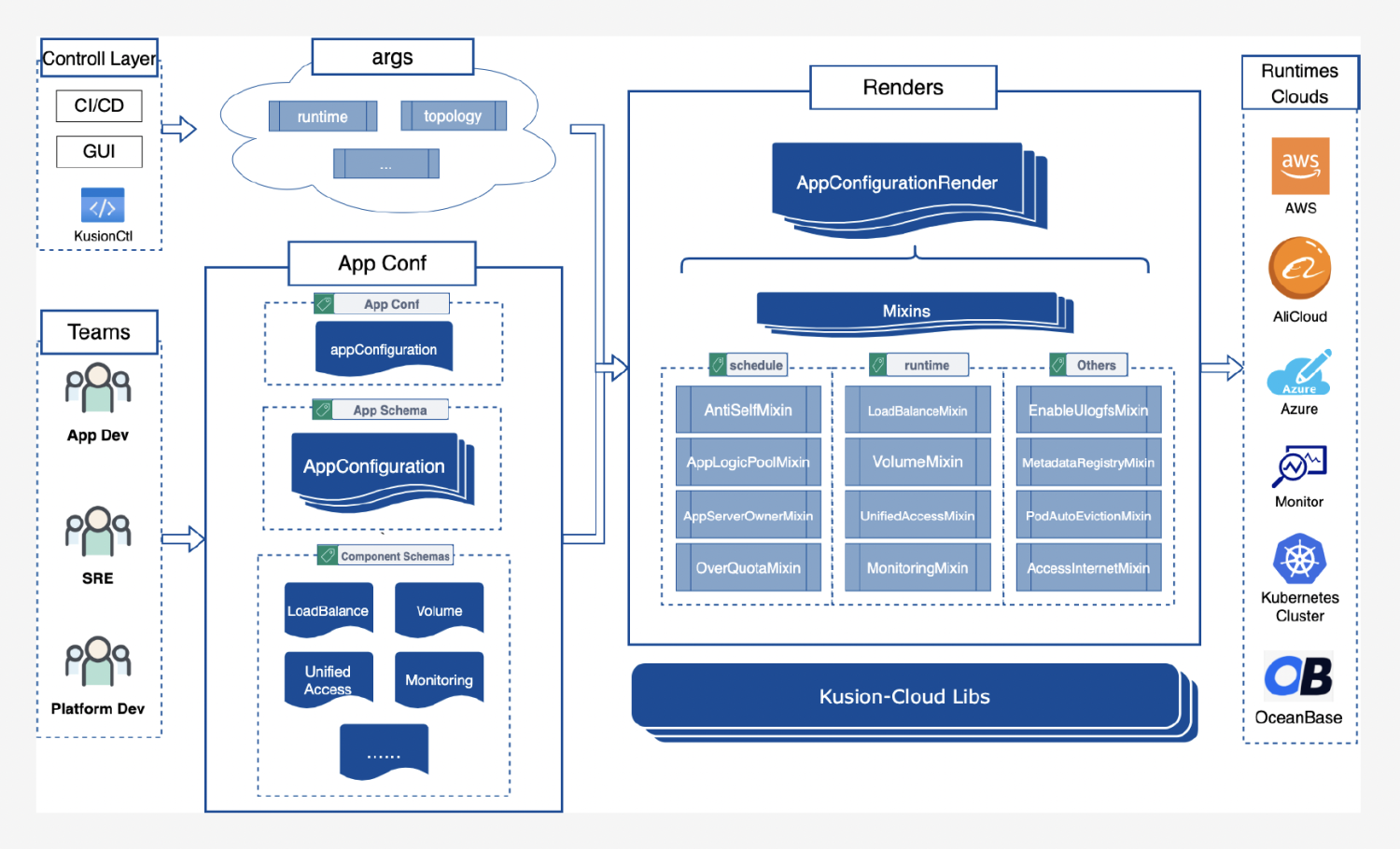
In the platform engineering practice of Ant Group, we have strengthened the client-side working mode. We write and maintain the models, orchestration, constraints and policies around the application ops life cycle in the shared codebase Konfig through the record and functional language KCL. KCL is a static and strongly typed language for application developers with programming ability, and provides the writing experience of a modern high-level language with limited functionality around domain purposes. Under such practices, KCL is not a language just for writing K-V pairs, but a language for platform engineering development. Application developers, SREs, and platform developers conduct dev collaboratively based on Konfig. They write configurations, and schema abstractions, functions, constraints and rules which are frequent and complex in the PaaS field through KCL native functions, that is, writing stable and scalable business models, business logic, error-proofing constraints, and environmental rules. The Konfig repository becomes a unified programming interface, workspace and business layer, while the KCL-oriented writing paradigm, which is secure and consistent, with low noise, low side effect and easy to automate, are more beneficial for long-term management and governance.
3. Divide and Conquer: Deconstructing the Scaling Problem
The idea of divide and conquer is the key to solving the scaling problem, whose efficiency is reflected from MapReduce to Kubernetes. In the field of large-scale delivery and operation, the classic operation platform tries to use the built-in unified model, orchestration, and provision technology in a black-box product to deal with full-scale business scenarios. Such a practice can be started easily and quickly and turns out to be effective on a small scale. However, as the adoption rate of different business groups increases and different requirements are put forward, it gradually enters into a state of fatigue with the constantly growing platform technology.
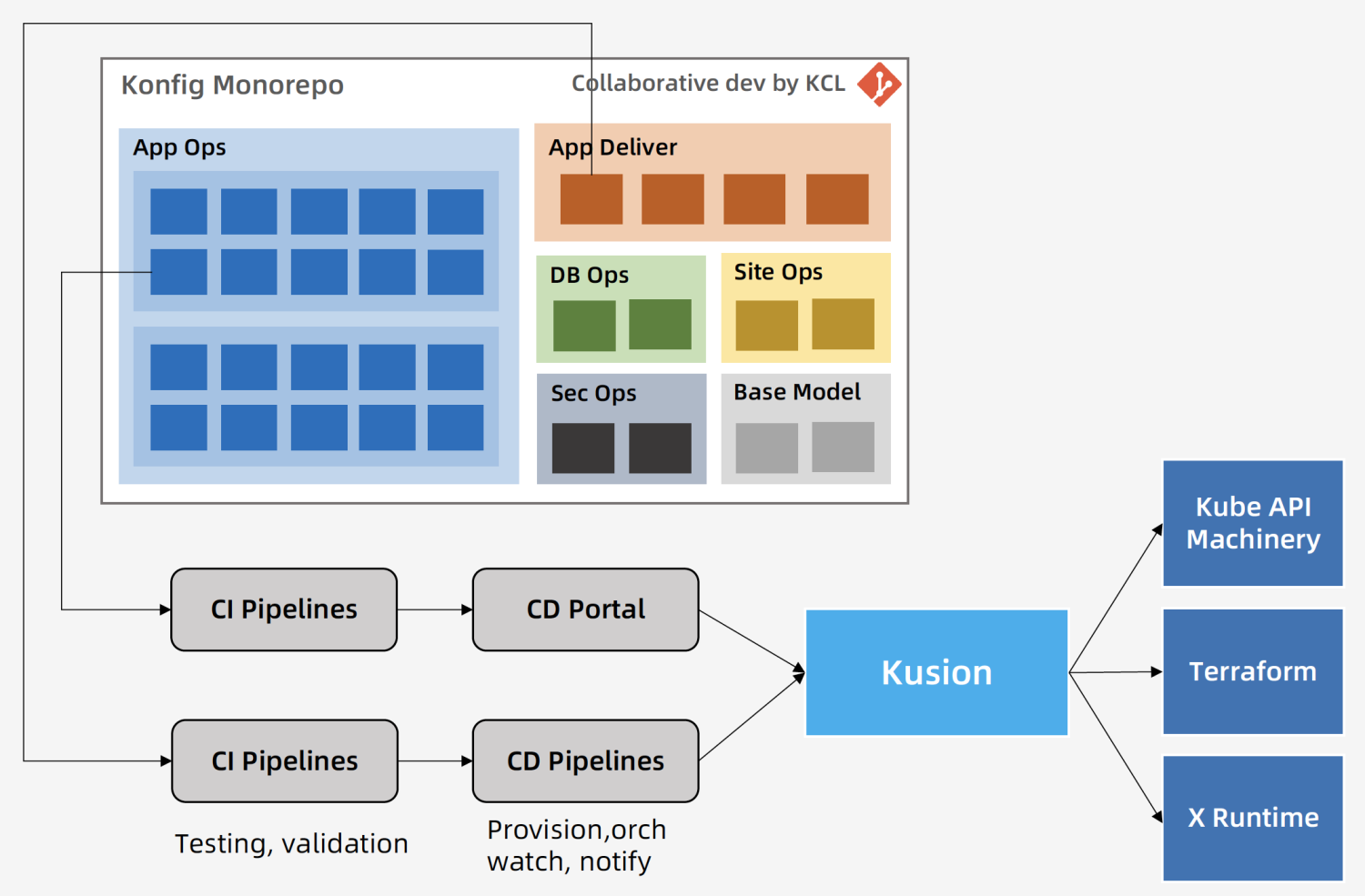
In Ant Group's practice, Konfig monorepo is the programming workspace opened by the internal engineering platform to developers, helping application developers to write configurations and policies around the application operation life cycle with a unified programming interface and tech stack, to integrate with existing and future platform and infrastructure, to create and manage cloud-native environments and RBAC-based permissions on demand, and to manage the delivery workflow through GitOps. Konfig monorepo provides an independent white-box programming space for different scenarios, projects and applications, whose intrinsic scalability comes from:
- Flexible, scalable, independent client-side engineering structure design
- The automatic merging technology of isolated config blocks supports the arbitrary and scalable organization of config blocks
- Static type system technology provides reusable and scalable type-based modeling and constraints in a modern programming language manner
- Project-grained GitOps CI workflow definition support
- Provision technology selection based on Kusion engine
Konfig monorepo provides divide-and-conquer, composable engineering structure design, code organization, modeling, workflow and provision tech selection support, meanwhile, it carries scalable business requirements with a consistent development model and workflow. The working method of the client-side ensures flexibility, scalability, and portability while reducing the steadily increasing pressure on the extension mechanisms of the server-side, such as Kubernetes API Machinery.
The following figure illustrates a typical automated workflow with a GitOps approach in the Konfig monorepo, starting from project-oriented code changes and reaching the runtime through configurable CI and CD processes. Compared to centralized black-box products, this mechanism is much more open, customizable and extensible, through which there’s no more necessity of designing clumsy configuration management portals for different business scenarios, projects, and applications.
4. Modeling: Marginal Revenue and the Long Tail
With the divide-and-conquer white-box engineering structure design, code organization, modeling, workflow and provision tech selection, we also need to consider how to work with platform APIs. The typical dispute within the enterprise is whether to face directly the platform details or to design an abstraction, which eventually grows into such kind of dispute between explicit and implicit concepts.
The abstract implicit method is a usual choice for platform engineers for non-expert end users, who want to design an easy-to-understand and easy-to-use application model or Spec abstraction, which is isolated from specific platform technical details, in order to reduce the end-user's burden on cognizing and enhances the performance of preventing errors by reducing detail perception. However, most operation platform developers tend to design a powerful and unified application model or Spec abstraction. In practice, they often encounter the following obstacles:
- With the increasing adoption rate of different business groups within the enterprise, it is difficult to implement unified modeling. The most typical case in Ant Group is the huge difference between Infra projects and SaaS applications. Java-based SaaS applications are easy to be unified, while Infra applications often need to be designed separately.
- With a large number of platform technologies in the enterprise, the unified model itself is difficult to be stabilized, especially in response to continuously changing business needs and platform demand growth driven by technology. In Ant Group's practice, delivery and operation are affected by various factors and thus have great instability. At the same time, the business requirements for
deliverable,runtime,security, andinstrumentationaround the application operation life cycle are also increasing. Taking instrumentation as an example, the rapidly increasing demand for application runtime observability and SLO definition in the past two years directly drives changes in end-user usage. - The general problem of abstract models is that a reasonable model needs to be well designed for end users, meanwhile, the API details of the platform must be kept in sync.
In Ant Group's practice, we adopt an abstract model for end-users, which refers to application developers, and solve several key problems through the following ideas:
- Modeling for typical applications or scenarios (such as Ant Group's Sofa application), these models are developed by platform developers together with platform SREs and maintained together with application developers to achieve a balance between user experience, cost and standard compatibility. In Ant Group's practice, the information entropy convergence ratio of the abstract model is about 1:5, and the marginal benefit of modeling investment is guaranteed through extensive high-frequency usage.
- For non-typical user applications or scenarios, platform developers and platform SRE support application developers to design application models. Mechanisms such as KCL schema and mixin help users to model, abstract, inherit, combine, reuse, and reduce repetitive code. Such modeling design work is one of the key points in the field of application PaaS, and we need a more reasonable division of labor for such a scenario. Finally, a large number of "non-standard" platform applications were adopted and managed in an accordant way within Ant Group for the first time, which solved the long tail problem effectively. In a typical collaborative mode, platform developers and platform SREs write base components of platform capability, thus becoming “Enablers”, and helping application developers "build building blocks” quickly by using base components to complete their application models.
- For platform technology, we provide the generation tool from platform API Spec to KCL schema code, natively support the compile-time selection of different Kubernetes API versions through combined compilation, and solve the flexible requirements of mapping application models to different versions of Kubernetes clusters in internal practice. At the same time, KCL supports the writing of in-schema constraints and independent environmental rules. In addition, KCL also provides the deprecated decorator to support the force deprecation of the model or model attribute. Through robust complete modeling and constraint mechanism on the client side, general problems such as configuration errors and schema drift are exposed at compile time. Due to the left-shifted problem found before runtime, runtime errors or failures are avoided while pushing to the cluster, which is also a necessary requirement for the stability of the production environment in the enterprise, especially in an enterprise with high-level risks.
Expert users of the underlying platform technology are usually very familiar with a specific technical domain and prefer to work in an explicit way that faces platform details. The KCL language provides the necessary dynamic and modular support and ensures stability through a static type system and constraint mechanisms. However, the explicit method cannot solve the problem that expert users are not familiar with the details of using cross-domain platform technologies, nor can it solve the problem of the scalability and complexity of platform technologies today. In Ant Group's small-scale YAML-based explicit engineering practice, facing a large number of highly open and configurable platform technologies, the complexity grows continuously with the utilization rate of platform technologies, and ends up in a rigid state that is hard to read, write, constrain, test, and maintain.
5. Automation: New Challenges
Automation is a classic domain in the field of infrastructure operation. With the wide and rapid adoption of cloud-native concepts and technologies, the ability to automatically integrate turns out to be the basic requirement of enterprise operation practice. Open source, highly configurable CI and CD technologies are gradually adopted by enterprises. The black-box "product" approach that cannot be integrated is gradually weakened and replaced by a flexible orchestration approach. The main advantages of this practice lie in its powerful customize orchestration and linking capabilities, high scalability as well as good portability. Especially in the Kubernetes ecosystem, the GitOps method has a high adoption rate and a natural affinity with configurable CI and CD technologies. Such changes are also promoting the gradual transformation of the work order and product centric workflow into a self-service and engineering efficiency platform centric workflow, and the operational capability of the production environment has become an important part of the automatic workflow. In the open source community, the technology innovation of the abstraction layer for different engineering efficiency platforms is also active in progress. The developers on the platform side hope to get through the CI and CD process applied to the cloud environment through the shortest cognitive and practical path.
In Ant Group's engineering practice, the engineering efficiency platform is deeply involved in the open automation practice of Konfig monorepo, and our practice direction is also highly aligned with the technological roadmap of the engineering efficiency platform. In the collaborative work of several people to dozens or even hundreds of people, workflow design for operation scenarios, high-frequency code submission and pipeline execution, real-time automated testing and deployment pose several challenges to the engineering efficiency platform. Especially the diverse businesses in monorepo require independent and powerful workflow customization and operation support, as well as parallel workflow execution capabilities with high real-time and strong SLO guarantee. The requirements of the single-repository mode are hugely different. Most configuration languages are interpreted languages, while KCL is designed as a compiled language, implemented by Rust, C and LLVM optimizer, to provide high-performance compile-time and runtime execution for large-scale KCL files. At the same time, KCL can be compiled to native code and wasm binary to meet various runtimes execution requirements. In addition, the storage and architecture design of Git is different from the Citc/Piper architecture, and not suitable for monorepo of large-scale code. Fortunately, we have not encountered a big problem with the scale of code today. Meanwhile, we’re working together to solve problems and hope to solve them gradually as the practice deepens.
6. Collaborative Culture: A More Important Thing
The above technologies, tools and mechanisms are very important, but I must say that for engineering and DevOps, the culture of collaboration, cooperation and sharing among groups and teams is more important, because it’s work composed of people, which means people and culture are actually the key points. Within an enterprise full of team silos or isolated teams, people tend to pursue a closed and bad engineering culture, thus we usually see a large number of private code bases and private documents, the judging and working method of small isolated groups. Teams that are supposed to work closely together actually do their own thing and chase after their own private goals. I think it’ll be very difficult to do anything at scale in a culture like this. So if your company or team plans to adopt DevOps at scale, the most important thing is to communicate extensively and to start the culture construction, because it’s not just such a kind of issue concerning a few persons, and it’s also quite difficult and unmanageable.
In Ant Group's practice, there are always various difficulties in the initial stage, and everyone's concerns about the self-service mechanism and collaborative culture are particularly obvious, such as "I need to write code?" "My code is actually in the same codebase with other teams?", "The job I'm in charge of is not easy, it won't work this way" are typical. Fortunately, we ended up with a virtual organization for common goals, with full support from partners and leaders, and we reached a consensus in the mass. Although the application developers are always complaining about the technology, workflow and mechanism, and hope to obtain a better user experience, which is understandable in deed, the application developers themselves are not the meant obstacle. The real obstacle firstly comes from the operation platform dev team itself. I see that the DevOps ideal of some companies turns into that the operation platform team does all the work for the application developers, even prevents users from accessing labor tools such as code and toolchains, and rushes to hide behind the existing GUI product, which deviates from the original intention and underestimates the capabilities and creativity of the users. Secondly, the obstacles also come from the technical leaders of some platform technical teams. It is difficult for them to give up focusing on the existing work that has lasted for many years, and then accept a new user service model. The feasible way is to let them understand the meaning and vision of the work, and gradually exert influence on them step by step and stage by stage.
7. Summary
After more than a year of practice, 400+ developers have directly participated in the code contribution of Konfig monorepo, and managed more than 1500 projects. Among them, the ratio of platform developers together with platform SREs to application developers is less than 1:9. Some of these application developers are the application owners themselves, and some are representatives of the application dev team, which is up to the application team itself. Through continuous automation capability building, 200-300 commits occur every day based on the Konfig monorepo, most of which are automated code modifications, about 1k pipeline task executions and nearly 10k KCL compilation executions. Today, if you compile the full code in Konfig once and output it, 300W+ lines of YAML text will be generated. A release operation process requires multiple compilations with different parameter combinations. Through the lightweight and portable code base and toolchains, we have completed a significant external private cloud delivery, eliminating the pain of transforming and porting a series of legacy operation platforms. Inside Ant Group, we have served several different operation scenarios, and are expanding the scale and exploring more possibilities.
Finally, I would like to talk about the next step. There’re still possibilities and potentialities for us to keep improving our technology and tools in terms of usability and user experience. More user feedback and continuous improvement are always needed, and there is no shortcut to a good user experience. In the aspect of testing, we provide simple integration testing methods, which play the role of smoke testing, however, it is far from enough. We are trying to ensure correctness based on schema constraints and environmental rules rather than tests. In terms of work interface, we hope to build an IDE-based dev workspace and continue to enhance and optimize the internal workflow experience. At the same time, we hope to continue to improve coverage and technical capabilities. In addition, we also hope to apply the practice method more widely in CI and operation workflow, as well as other scenarios, to shorten end-user awareness and end-to-end workflow. At present, KusionStack is still in the very early stage of open source, and there is a lot of work to do in the future. The most important thing is that we hope to share the concepts and practices of our platform engineering with more companies and teams, to bring about and witness some interesting changes together.
8. Reference
- https://kusionstack.io/docs/user_docs/intro/overview
- https://platformengineering.org/blog/what-is-platform-engineering
- https://internaldeveloperplatform.org/what-is-an-internal-developer-platform/
- https://web.devopstopologies.com/#anti-types
- https://github.com/KusionStack/kusion
- https://github.com/KusionStack/KCLVM
- https://kcl-lang.io/
- https://kusionstack.io/docs/user_docs/concepts/konfig
- https://kcl-lang.io/blog/2022-declarative-config-overview#35-performance
- https://cacm.acm.org/magazines/2016/7/204032-why-google-stores-billions-of-lines-of-code-in-a-single-repository/fulltext